Parrainé par Teledyne FLIR
L’apprentissage profond s’est développé rapidement au cours des dix dernières années avec l’introduction de réseaux de neurones open source et la disponibilité de grands ensembles de données annotés rendus possibles par les efforts des universitaires et des grandes plates-formes technologiques. Le concept de réseau neuronal perceptron a été décrit pour la première fois dans les années 1950, mais ce n’est que récemment que les données d’entraînement adéquates, les cadres de réseau neuronal et la puissance de traitement requise se sont réunis pour lancer la révolution de l’IA. La division OEM de caméras infrarouges Teledyne FLIR se concentre sur l’extraction de l’aide à la décision à partir de caméras vidéo infrarouges et visibles déployées dans un large éventail d’applications, notamment la sécurité automobile, l’autonomie, la défense, la navigation maritime, la sécurité et l’inspection industrielle. Grâce à un travail de développement intensif et continu, Teledyne FLIR propose des solutions d’imagerie multispectrale optimisées pour la taille, le poids, la puissance et le coût (SWaP + C) en s’appuyant sur les processeurs de vision les plus avancés, les réseaux de neurones efficaces, les grands ensembles de données d’images et les données d’images synthétiques.

CONSIDÉRATIONS MATÉRIELLES
Les développeurs prennent de nombreuses décisions lors de la conception de caméras avec une intelligence embarquée à la périphérie. Le plus percutant est la sélection du processeur de vision. Jusqu’à récemment, ce choix était essentiellement limité à NVIDIA, en raison de leur technologie de traitement graphique supérieure qui a été mise à profit pour les exigences de calcul hautement parallèles des réseaux de neurones. En outre, la majeure partie de la propriété intellectuelle (PI) open-source pour la formation réseau et le déploiement d’exécution a été développée sur et pour l’écosystème NVIDIA. Bien que NVIDIA continue d’être une plate-forme puissante, le coût, la taille et la consommation d’énergie peuvent potentiellement limiter la viabilité des caméras intelligentes compactes. Au cours des dernières années, les principaux fournisseurs de processeurs de vision, notamment Qualcomm, Intel, Ambarella, Xilinx, Altera, MediaTek et d’autres, ont développé des architectures de puces qui comportent des cœurs de réseau neuronal ou des tissus de calcul conçus pour traiter des charges de calcul de réseau neuronal à une puissance et un coût nettement inférieurs.
Un nombre croissant de fournisseurs proposent des processeurs de vision puissants; cependant, il n’est souvent pas possible pour les petits développeurs de s’approvisionner en processeurs de pointe directement auprès des fabricants qui dirigent généralement les clients de plus petits volumes vers des entreprises partenaires offrant des solutions SOM (system on module) et un support technique. Bien que ce soit une bonne option pour certains développeurs, il est souvent avantageux de travailler directement avec le fournisseur de processeurs de vision, car l’intégration de routines d’exécution complexes multithread nécessite un soutien étroit de la part des fournisseurs de processeurs de vision.
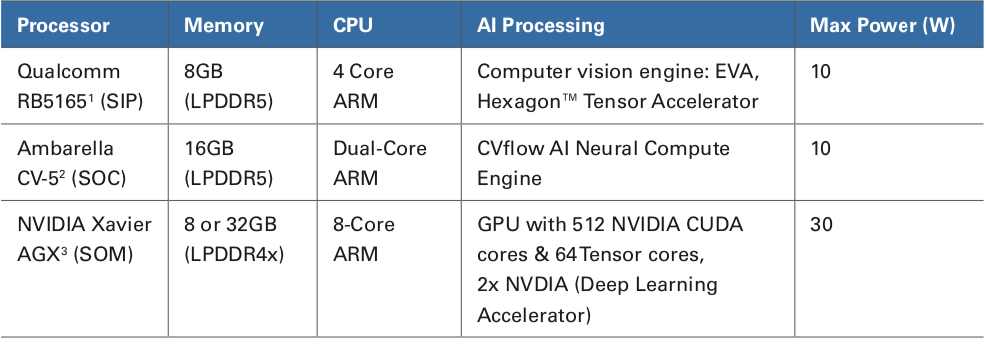
Tableau 1. Exemples de Plates-Formes de Calcul
- https://www.qualcomm.com/media/documents/files/qualcomm-robotics-rb5-platform-product-brief.pdf
- https://3vpstm1hc6e52739x31131p2-wpengine.netdna-ssl.com/wp-content/uploads/Ambarella_CV5_Product_Brief_15JAN2021.pdf
- https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/jetson-agx-xavier/
Il y a plusieurs considérations importantes lors de l’évaluation des plates-formes de calcul AI. Le premier est le nombre effectif d’unités logiques arithmétiques (ALU) disponibles pour effectuer des charges de travail d’IA. Il est courant d’utiliser des accélérateurs neuronaux, des GPU, des DSP et des processeurs pour certaines parties de la charge de travail. Lors d’une sélection de matériel, il est important de comprendre les forces et les faiblesses de chacun et de budgétiser les ressources en conséquence. La possibilité d’exécuter plusieurs routines logicielles simultanément est essentielle au logiciel de reconnaissance automatique de cibles. S’il n’y a pas de puissance de traitement adéquate, le logiciel doit adapter les différentes routines à la tranche de temps disponible, ce qui entraîne une perte d’images. La deuxième considération importante est le type et la quantité de mémoire à laquelle le processeur peut accéder. Une mémoire suffisante et rapide est importante pour obtenir une inférence à des fréquences d’images élevées tout en exécutant toutes les routines logicielles telles que la perspective de distorsion, le flux optique, le suivi d’objets et les détecteurs d’objets.
Teledyne FLIR a sélectionné des processeurs avec mémoire LPDDR5 intégrée avec au moins 8 Go conçus dans plusieurs caméras intelligentes, y compris la nouvelle caméra de sécurité Triton ™. Le logiciel Teledyne FLIR AI stack nécessite entre 3 et 10 watts lorsqu’il fonctionne sur Ambarella CV-2 ou Qualcomm RB5165. La consommation d’énergie est gérée en sélectionnant des réseaux et des routines de proposition pour s’adapter au budget d’énergie spécifié par l’intégrateur. Les performances de détection d’objets sont affectées par ces configurations, mais des gains de performances continuent d’être réalisés avec des réseaux neuronaux plus efficaces et du matériel de processeur de vision de nouvelle génération de nœuds.
CONSIDÉRATIONS ET PERFORMANCES DU RÉSEAU NEURONAL CONVOLUTIF
Bien qu’il existe un nombre accru de choix de processeurs pour exécuter des modèles en périphérie, la formation des modèles est généralement effectuée sur du matériel NVIDIA en raison de l’environnement de développement d’apprentissage profond très mature basé sur et pour les GPU NVIDIA. La formation en réseau neuronal est très exigeante en termes de calcul et lors de la formation d’un modèle à partir de zéro, un développeur peut s’attendre à des temps de formation allant jusqu’à 5 jours sur une machine GPU haut de gamme. La formation en réseau peut être effectuée sur des plates-formes de services cloud populaires, mais les coûts de calcul sur ces plates-formes sont coûteux et le long temps de téléchargement et de téléchargement des données est une considération. Pour soutenir le développement, Teledyne FLIR exploite des serveurs locaux dédiés pour la formation réseau afin de gérer le calendrier et les coûts.
La deuxième décision qu’un développeur doit prendre est de sélectionner l’architecture du réseau de neurones. Dans le contexte de la vision par ordinateur, un réseau de neurones est généralement défini par sa résolution d’entrée, ses types d’opérations et sa configuration / son nombre de couches. Ces facteurs se traduisent tous par le nombre de paramètres entraînables qui ont une forte influence sur la demande de calcul. Les exigences de calcul se traduisent directement par la consommation d’énergie et les charges thermiques qui doivent être prises en compte lors de la conception des produits.
L’espace commercial dicte des compromis entre la précision de la détection d’objets et des fréquences d’images élevées pour la bande passante de calcul d’un processeur de vision donné. Les utilisateurs de caméras vidéo exigent généralement une détection d’objet rapide et précise qui permet une réponse humaine et automatique par des systèmes de contrôle de mouvement ou des alarmes. Un bon exemple est le freinage d’urgence automatique (AEB) pour les véhicules de tourisme, où un système basé sur la vision peut détecter un piéton ou d’autres objets en quelques millisecondes et déclencher un freinage pour arrêter le véhicule. Un autre exemple est un système de contre-drones qui doit suivre les objets d’intérêt et fournir une rétroaction aux systèmes de contrôle de mouvement pour diriger les contre-mesures visant à désactiver les drones.
Tableau 2. Performances populaires du réseau neuronal Open Source et Teledyne FLIR testées par Teledyne FLIR Exécutant le Jeu de données de test COCO 2018 sur un NVIDIA TX2
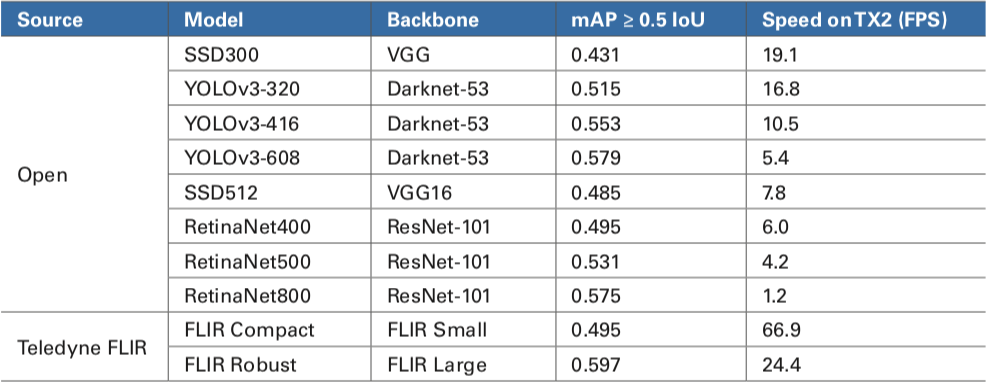
À des fins de comparaison, le tableau 2 comprend plusieurs réseaux de neurones open source et Teledyne FLIR populaires et leurs performances telles que testées par Teledyne FLIR exécutant le COCO4 jeu de données de test sur un NVIDIA TX2. La précision moyenne moyenne (mAP) est la mesure de notation la plus courante dans la détection d’objets. L’intersection sur union (IoU) est utilisée pour déterminer si une détection d’objet est une « correspondance“ ou une ”erreur « , comme le montre la figure 1. Les correspondances élevées, les échecs faibles et les faux positifs faibles sont en corrélation avec des scores de carte plus élevés. Le tableau 2 comprend les scores cartographiques de chaque modèle en utilisant une valeur IoU supérieure ou égale à 0,5 et la vitesse de traitement résultante en images par seconde (FPS).
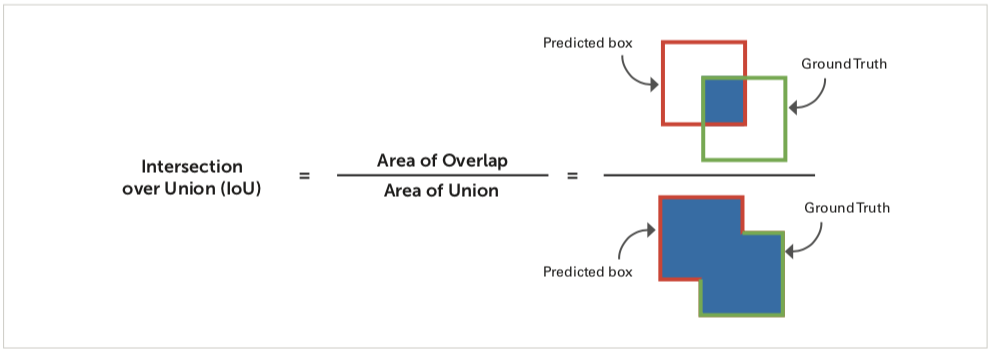
Figure 1 – Illustration de la mesure du rendement de l’IoU
4. COCO – Objets communs dans le contexte (cocodataset.org)
En plus de comprendre les performances des modèles, les data scientists doivent analyser la cause des faux positifs et des faux négatifs ou des “ratés ». » Teledyne FLIR a développé Conservator™, un logiciel de gestion d’ensembles de données par abonnement qui inclut Insights™, un outil de performance de modèle local capable de visualiser les performances du modèle. Il peut être utilisé pour explorer et identifier de manière interactive les zones où le modèle fonctionne mal, ce qui permet au data scientist d’étudier les images d’ensembles de données d’entraînement spécifiques à l’origine des détections manquées. Les développeurs peuvent rapidement modifier ou augmenter les données d’entraînement, se recycler, tester à nouveau et itérer jusqu’à ce que le modèle converge vers les performances requises. La figure 2 comprend un exemple de sortie illustrant les performances du modèle à chaque point de la séquence vidéo. La zone de la boîte englobante à partir de la vérité au sol, des correspondances d’objets, des erreurs d’objets et des faux positifs sont tracées côte à côte pour aider à identifier les zones préoccupantes.
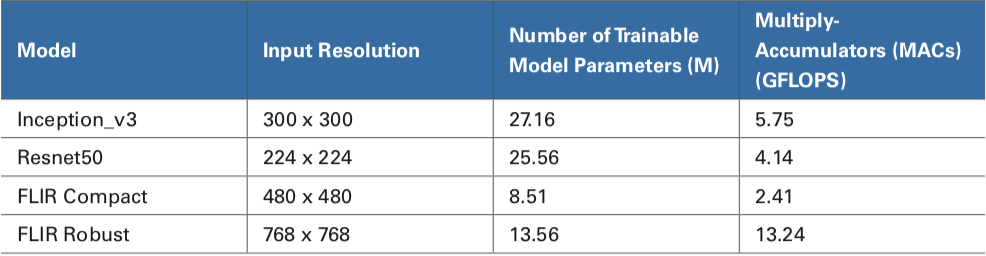
Il est instructif de comprendre le nombre de calculs effectués par les réseaux de neurones. Pour les applications vidéo telles que les systèmes de sécurité automobile, il est souhaitable que des calculs soient effectués sur chaque image vidéo. Il est essentiel d’obtenir des détections d’objets rapides pour éliminer les délais de réponse. Pour d’autres applications, y compris les systèmes de contre-drones (C-UAS) ou de contre-drones, les métadonnées de détection rapide et de localisation des objets sont une entrée essentielle dans un tracker vidéo qui contrôle la caméra et les actionneurs de pointage des contre-mesures. Le tableau 3 comprend les paramètres du réseau neuronal, la résolution d’entrée et les demandes de traitement associées pour quatre exemples de modèles à des fins d’information et de comparaison. Ces estimations ne tiennent pas compte de la façon dont l’architecture utilise le matériel spécifique, il est donc important de noter que le moyen le plus fiable de comparer un modèle est d’exécuter le modèle sur le périphérique réel.
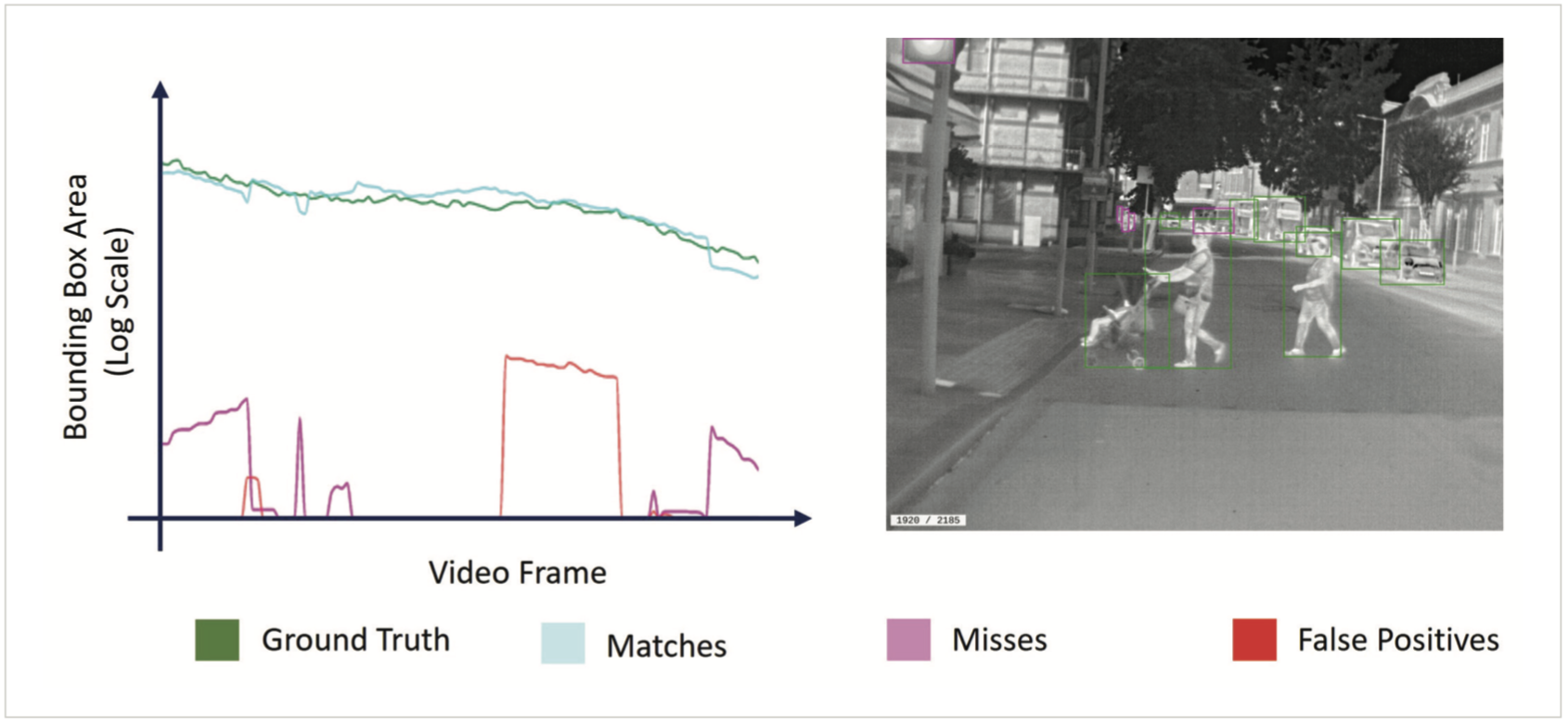
Figure 2. Exemple de Sortie Logicielle de Performance de Modèle Visuel de Conservateur et Image Infrarouge Associée
Tableau 3. Exemple de Demandes de Traitement de Réseau Neuronal et de Résolution d’entrée
À la fin d’un processus de formation, le modèle doit généralement être converti pour s’exécuter sur la structure d’exécution spécifique du processeur de vision cible. Le processus de traduction et d’ajustement est extrêmement complexe et nécessite un ingénieur logiciel qualifié. Cela a été un point de friction important dans le déploiement plus rapide de l’IA dans les caméras. En réponse, un consortium industriel a créé ONx AI, un projet open source qui a établi une norme de format de fichier modèle et des outils pour faciliter l’exécution sur un large éventail de cibles de processeur. Comme ONX devient entièrement pris en charge par les fournisseurs de processeurs de vision et la communauté des développeurs, les efforts requis pour déployer des modèles sur différents matériels réduiront considérablement le point difficile pour les développeurs.
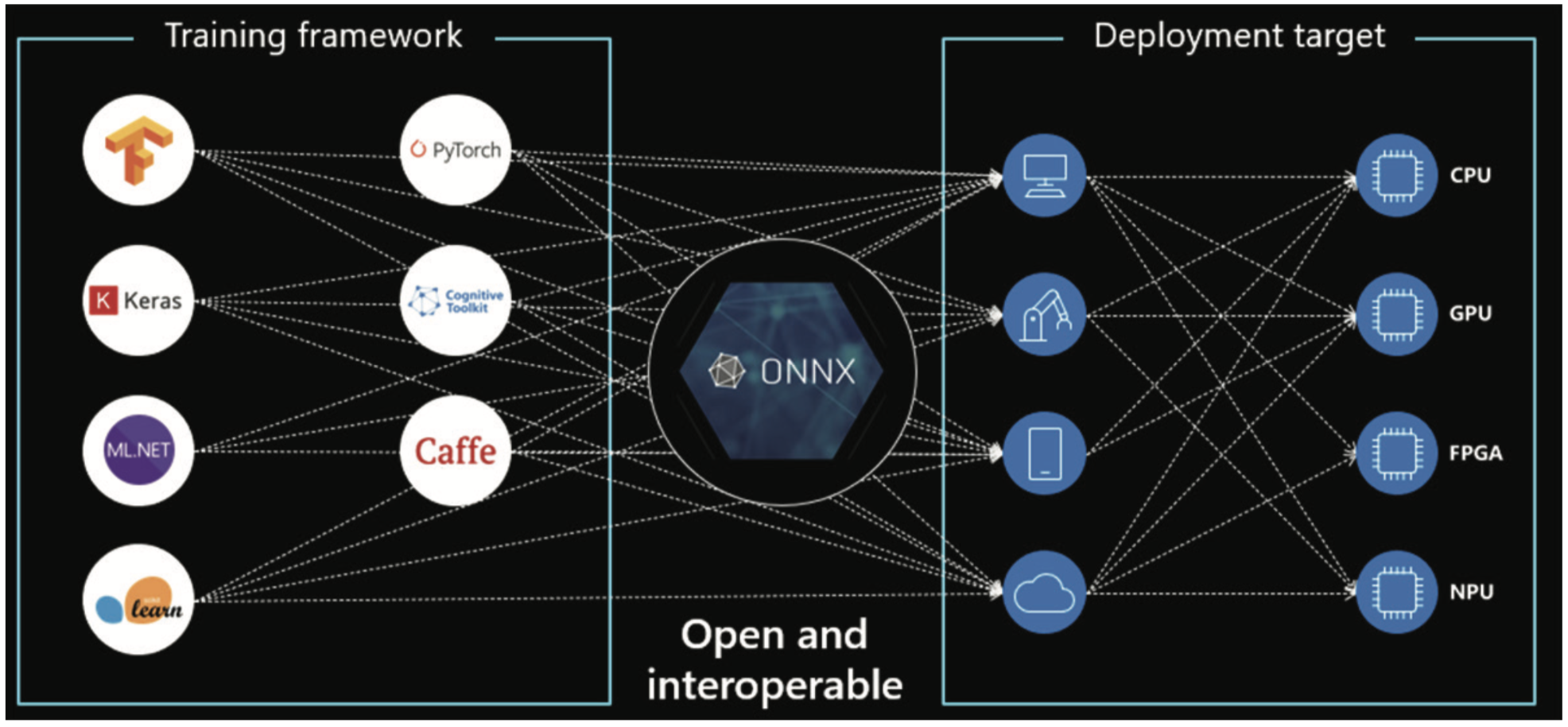
Figure 3 : Source d’image ONX AI https://microsoft.github.io/ai-at-edge/docs/onnx/
La pile d’IA Teledyne FLIR utilise une combinaison de technologies de vision par ordinateur pour gérer les demandes de calcul tout en maximisant la confiance dans l’état de la cible. Le cadre abrite un large éventail de réseaux et de configurations optimisés pour les applications qui combinent de manière transparente des routines, notamment la détection de mouvement, la recherche stochastique, la classification à grains fins, le suivi multi-objets et la fusion de capteurs avec des entrées externes telles qu’un radar. Le framework permet de sélectionner n’importe quelle combinaison de réseaux et de routines lors de l’exécution à l’aide de configurations spécifiques à l’application.
Les modèles actuels offrent des entrées de pixels aussi grandes que 1024 x 768, ce qui réduit le besoin de décimer une image pour l’intégrer dans un modèle lors de l’exécution de l’inférence sur des caméras à méga pixels.Cela peut se traduire directement par des performances de détection d’objets à longue portée en maximisant le nombre de pixels sur la cible. De plus, cela garantit une entrée maximale de pixels dans des classificateurs à grain fin qui peuvent produire des caractéristiques d’objet telles qu’un modèle de véhicule spécifique ou une détection d’ami ou d’ennemi.
DÉVELOPPEMENT DE PILE D’IA TELEDYNE FLIR
La figure 4 comprend des exemples de frameworks, d’ensembles de données, de bibliothèques, de réseaux de neurones et de matériel qui composent la pile d’IA typique. Teledyne FLIR développe et fabrique des caméras infrarouges à ondes longues (LWIR), infrarouges midwave (MWIR) et à lumière visible qui peuvent et sont en cours de développement pour utiliser l’IA à la périphérie. Compte tenu des exigences et du manque d’outils matures associés à la détection multispectrale, un logiciel unique, des ensembles de données et plus encore ont été développés pour prendre en charge l’IA en périphérie à l’aide des capteurs Teledyne FLIR.
Teledyne FLIR utilise le framework PyTorch, qui est étroitement intégré à Python, l’un des langages les plus populaires pour la science des données et l’apprentissage automatique. PyTorch prend en charge les graphiques de calcul dynamiques permettant de modifier le comportement du réseau par programmation au moment de l’exécution. De plus, la fonctionnalité de parallélisme des données permet à PyTorch de répartir le travail de calcul entre plusieurs GPU ainsi que plusieurs machines pour réduire le temps d’entraînement et améliorer la précision.
Les ensembles de données pour la détection d’objets sont de grandes collections d’images qui ont été annotées et organisées pour l’équilibre des classes et des caractéristiques telles que le contraste, la mise au point et la perspective. Il est recommandé dans l’industrie de gérer un ensemble de données comme le code source d’un logiciel et d’utiliser le contrôle des révisions pour suivre les modifications. Cela garantit que les modèles d’apprentissage automatique maintiennent des performances cohérentes et reproductibles. Si un développeur rencontre des problèmes de performances avec un modèle, les data scientists peuvent rapidement identifier où augmenter l’ensemble de données pour créer un cycle de vie d’amélioration continue. Une fois qu’une amélioration vérifiée a été apportée, la modification des données est enregistrée avec une entrée de validation qui peut ensuite être examinée et auditée. Teledyne FLIR Conservator, un logiciel de gestion d’ensembles de données par abonnement, facilite le contrôle des révisions sur les lacs de données à l’échelle du téraoctet, ainsi que de solides fonctionnalités de protection des données et d’accès pour permettre aux équipes distribuées. En outre, plus de 6,1 millions d’images multispectrales et plus de 25 millions d’objets annotés (en décembre 2021) sont disponibles pour les abonnés.
Bien que des ensembles de données open source tels que COCO soient disponibles, il s’agit de collections d’images en lumière visible contenant des objets communs à courte portée capturés depuis une perspective au niveau du sol. Teledyne FLIR se concentre sur les applications qui nécessitent des images multispectrales prises de l’air au sol, du sol à l’air, à travers l’eau et d’objets uniques, y compris des objets militaires. Pour faciliter l’évaluation de l’imagerie thermique par les développeurs de systèmes de sécurité et d’autonomie automobiles, Teledyne FLIR a créé un ensemble de données open source comprenant plus de 26 000 trames thermiques et visibles appariées. Étant donné que de nombreux utilisateurs comptent sur les caméras Teledyne FLIR pour classer avec précision les objets à de longues distances, des images de cibles à différentes distances ont été ajoutées pour garantir le bon fonctionnement des modèles comme des détecteurs de petits objets.

Figure 4. Pile d’IA Représentative
Dans le monde réel, les objets sont vus dans des combinaisons presque infinies de distance, de perspective, d’environnements d’arrière-plan et de conditions météorologiques. La précision des modèles d’apprentissage automatique dépend en grande partie de la mesure dans laquelle les données d’entraînement représentent les conditions de terrain. Teledyne FLIR a développé un outil qui analyse l’imagerie d’un jeu de données et quantifie la distribution des données en fonction de l’étiquette de l’objet (% d’images de personne, de voiture, de vélo, etc.), la taille de l’objet, le contraste, la netteté et la luminosité. L’outil est ensuite capable de corréler les performances du modèle aux caractéristiques des données et de produire une fiche technique au format PDF pour chaque nouvelle version du modèle. Cette analyse est très importante pour les scientifiques des données et est précieuse dans l’itération continue du développement de modèles.
Le temps et les dépenses nécessaires pour créer de grands ensembles de données de formation sont importants et nécessitent la collecte de données sur le terrain, la conservation des cadres, l’annotation et le contrôle de la qualité sur la précision des étiquettes. C’est un goulot d’étranglement dans le déploiement de l’IA. Teledyne FLIR a reconnu les données de formation comme un composant essentiel de la pile d’IA et, en réponse, s’est tournée vers le domaine des données synthétiques. Teledyne FLIR travaille en étroite collaboration avec CVEDIA, une entreprise de technologie de données synthétiques, pour développer les outils et la propriété intellectuelle nécessaires à la création de données et de modèles multispectraux à l’aide d’images de synthèse (CGI). Cet outil puissant permet la création d’images multispectrales de presque n’importe quel objet, quelle que soit la perspective et la distance. Le résultat est la possibilité de créer des ensembles de données d’objets uniques tels que des véhicules militaires étrangers, ce qui serait extrêmement difficile à faire en s’appuyant sur la collecte de données sur le terrain.
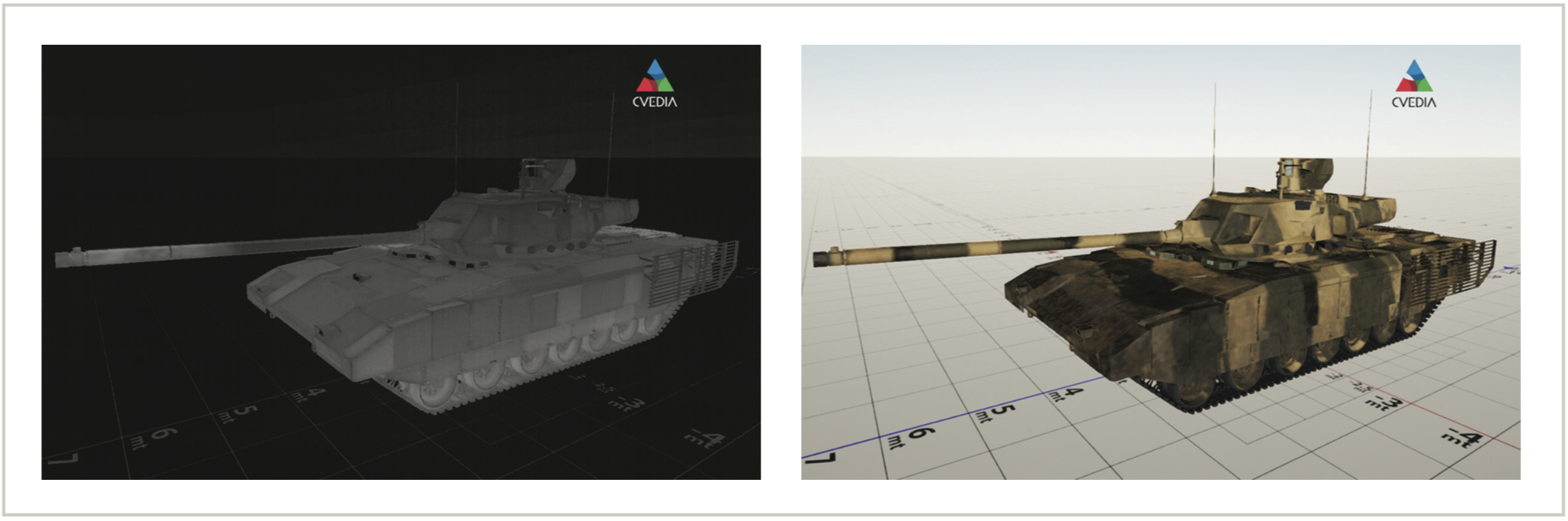
Figure 5: Données d’entraînement synthétiques en lumière LWIR et en Lumière Visible – Avec l’aimable autorisation de CVEDIA
L’IA À LA POINTE DE LA PRODUCTION
Il y a une convergence du développement et de la technologie permettant une voie plus claire pour déployer une IA abordable et fonctionnelle à la périphérie. Un matériel à moindre coût est publié avec des performances de traitement améliorées qui peuvent être utilisées avec des réseaux de neurones plus efficaces. Les outils logiciels et les normes visant à simplifier la création et le déploiement de modèles sont prometteurs et permettent aux développeurs d’ajouter de l’IA à leurs caméras avec un investissement monétaire moindre. La communauté open source et les normes de modèle de la communauté ONX contribuent également à l’accélération de l’IA à la périphérie.
Étant donné que les intégrateurs exigent une IA à la pointe sur les marchés de l’industrie, de l’automobile, de la défense, de la marine, de la sécurité et d’autres marchés, il est important de reconnaître les efforts d’ingénierie nécessaires pour déplacer une démonstration de preuve de concept d’IA à la pointe vers la production. Développer des ensembles de données de formation, combler les lacunes de performance, mettre à jour les données et les modèles de formation et intégrer de nouveaux processeurs nécessite une équipe aux compétences diverses. Les développeurs de systèmes d’imagerie devront examiner attentivement l’investissement requis pour développer cette capacité en interne ou lors de la sélection de fournisseurs pour prendre en charge leur pile d’IA.

© 2022Teledyne FLIR LLC. Tous droits réservés.